VideoVector platform showing indexes, processed media, and metadata detail
Media enrichment becomes expensive when every workflow depends on manual upload, review, copy, and export. Technical teams need a cloud-native pattern: media lands in storage, extraction runs automatically, structured metadata is generated, and downstream systems receive the result without manual handoff.
VectorMethods supports this pattern through VideoVector and media workflow automation. VideoVector can process video, audio, and image assets, run repeatable prompt executions, create time-stamped metadata, generate asset-level analysis, index searchable context, and deliver outputs into the rest of the stack.
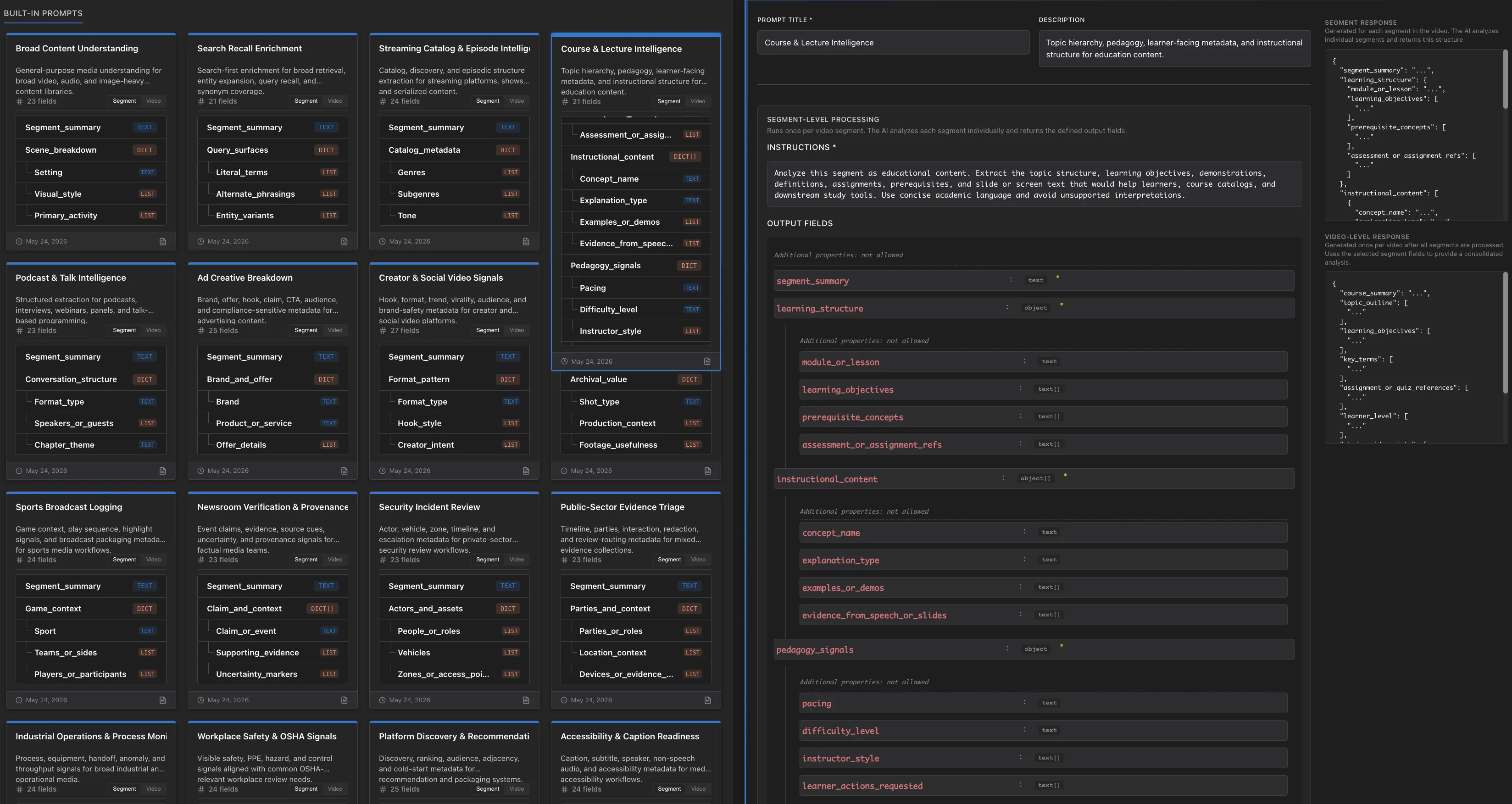
Built-in schemas for media workflows and structured extraction
The ingestion layer can connect to cloud storage systems such as GCS, S3, Azure, and R2, or to application-controlled uploads. Once media arrives, teams can apply extraction schemas for archive cataloging, sports moment analysis, lecture understanding, industrial review, security evidence, product discovery, or entertainment workflows.
The output is not just a summary. VideoVector can generate AI metadata extraction records with nested JSON, segment timestamps, searchable descriptors, asset-level classifications, and domain-specific fields. That output can be used for video scene extraction, video segment analysis, vector search for video scenes and events, and VideoRAG retrieval.
Automation needs clear handoff. The webhooks guide describes how downstream systems can react when processing completes or when results are ready. A webhook can update a catalog, start a review queue, notify an internal service, refresh a search index, or trigger another pipeline step.
For developers who need more control, the API exposes programmatic access to indexes, media, prompts, runs, search, exports, and webhook-oriented workflows. This lets engineering teams decide which work should be event-driven and which should be controlled directly by application code.
A common architecture looks like this: media arrives in cloud storage, VideoVector imports or processes it, an extraction schema creates time-stamped and asset-level metadata, embeddings make the asset searchable, and webhooks or exports send structured intelligence to the next system. That next system might be a CMS, MAM, warehouse, recommendation service, moderation queue, or internal analyst tool.
Teams planning governed or cross-system deployment can use the contact path to map a first automation workflow. The goal is not to replace existing media infrastructure. It is to add an intelligence layer that makes raw media usable by that infrastructure.
Cloud-native media enrichment is most valuable when it becomes repeatable. Once a schema works for one file, it can run across new uploads, archives, and recurring intake streams.